Apache Spark stands as a titan in big data processing, and at its core lies the secret sauce of transformations — operations that make Spark the go-to framework for distributed computing.
Let’s explore what these transformations are, why they’re vital, and how you can master them to build efficient, scalable data pipelines.

🌟 What Are Transformations?
Transformations in Apache Spark are operations applied to RDDs (Resilient Distributed Datasets), DataFrames, or Datasets that produce new datasets.
But here’s the Spark twist: Transformations are lazy! 😴 They don’t execute until an action (like count() or collect()) is triggered, which allows Spark to optimize the entire pipeline before execution.
This ensures that computations are efficient, reducing runtime and resource usage.
🔄 Types of Transformations
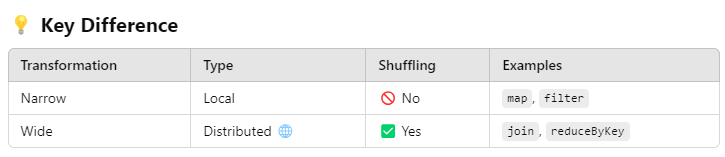
Transformations in Spark are of two types: Narrow and Wide.
1️⃣ Narrow Transformations
- Data in one partition directly maps to data in a new partition.
- 🚫 No shuffling of data between nodes.
- Examples:
map(): Apply a function to each element.filter(): Filter elements based on a condition.flatMap(): Similar tomap()but flattens the result.
Code Example:
rdd = sc.parallelize([1, 2, 3, 4, 5])
squared_rdd = rdd.map(lambda x: x**2)
print(squared_rdd.collect()) # Output: [1, 4, 9, 16, 25]
2️⃣ Wide Transformations
- Data from multiple partitions is shuffled across nodes 🌐.
- Essential for operations like grouping or aggregations.
- Examples:
reduceByKey(): Aggregate values by key.groupByKey(): Group data by key.join(): Combine data from two datasets based on keys.
Code Example:
key_value_rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
reduced_rdd = key_value_rdd.reduceByKey(lambda x, y: x + y)
print(reduced_rdd.collect()) # Output: [('a', 2), ('b', 1)]
⚙️ Why Are Transformations Important?
Transformations are the building blocks of Spark’s data processing framework. Whether you’re working on ETL pipelines, real-time analytics, or machine learning workflows, transformations help by:
✨ Optimizing workflows: Laziness allows Spark to optimize the entire process.
🌍 Scalability: Distributed transformations process massive datasets across clusters.
⚡ Flexibility: Work seamlessly with structured and unstructured data.
Best Practices for Transformations
- Minimize Wide Transformations: Reduce shuffling to improve performance.
- Partition Wisely: For
reduceByKeyorjoin, use partitioning to avoid unnecessary shuffling. - Leverage DataFrames: Use Spark SQL APIs for optimized transformations via the Catalyst engine.
🚀 Wrapping It Up
Transformations in Apache Spark are the key to unlocking its true power. They enable us to manipulate massive datasets efficiently while keeping code elegant and scalable.
🔑 Whether you’re a beginner or a pro, mastering transformations can take your Spark skills to the next level.
💬 Have questions or tips on using Spark? Let’s spark a conversation in the comments below!
#BigData #ApacheSpark #DataEngineering #DistributedComputing 🔥