Apache Spark is a fast, distributed computing system designed for processing large datasets with both batch and real-time processing capabilities. It offers fault tolerance and high scalability across a cluster of machines.
Key Components of Spark Architecture:
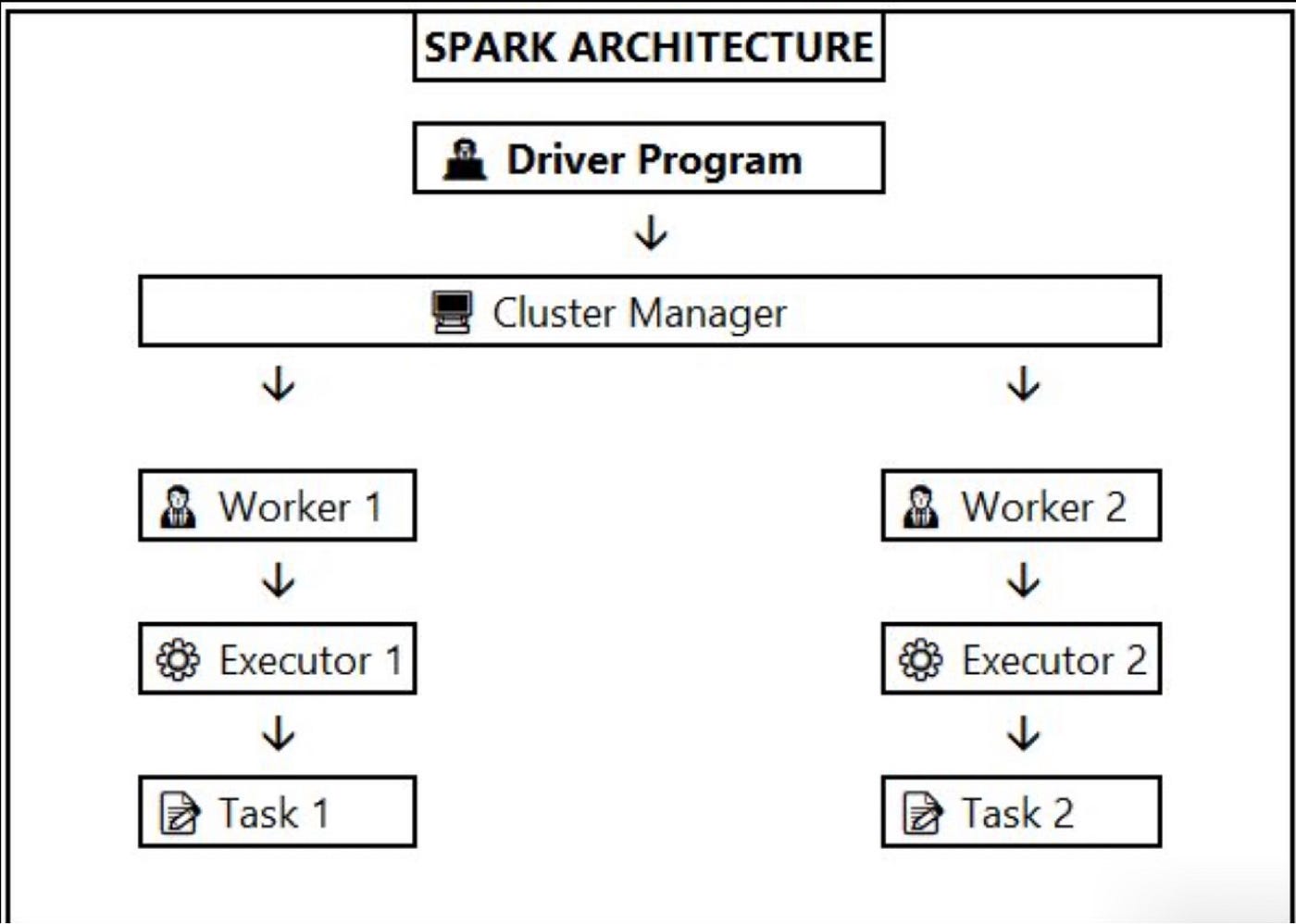
👨💻 Driver Program:
The entry point for a Spark application. It manages the Spark context and executes the job.
It communicates with the Cluster Manager to allocate resources on worker nodes.
🖥️ Cluster Manager:
Manages resources across the cluster. The common cluster managers are Standalone, YARN, and Mesos.
Allocates worker nodes and resources based on job requirements.
🧑💼 Workers:
These are the nodes that perform actual computations.
Each worker runs one or more Executors, which are JVM processes responsible for computation.
⚙️ Executor:
Executors execute tasks assigned by the driver and store data in memory.
They run on worker nodes and manage the data for a Spark application (storing RDDs).
📝 Task:
The smallest unit of work in Spark. A task is executed by an executor on a partition of the dataset.
📊 RDD (Resilient Distributed Dataset):
The core data structure in Spark. RDDs are immutable, distributed collections that can be processed in parallel.
They provide fault tolerance through lineage information.
🔗 DAG (Directed Acyclic Graph):
The DAG represents stages and their dependencies in a Spark job.
The Driver constructs the DAG, which is divided into stages and tasks for execution.
📈 Job, Stage, and Task:
Job: A complete unit of work submitted to Spark.
Stage: A set of tasks that can be executed in parallel.
Task: The smallest unit of execution.
Spark Execution Flow:
🚀 Submit Job: The user submits a job to the Driver Program.
🔍 DAG Construction: The driver creates a DAG representing the job.
🛠️ Job Division into Stages: The DAG is divided into stages based on dependencies.
📅 Task Scheduling: Tasks are scheduled and assigned to the Executors.
⚡ Execution: Executors process the data and perform tasks.
📤 Result Collection: The driver collects the results from the executors after task completion.
Conclusion:
Spark’s architecture provides a robust, fault-tolerant, and scalable solution for big data processing. With in-memory computation and DAG scheduling, Spark enables fast data processing for both batch and real-time workloads. By understanding Spark’s architecture, you can better leverage its capabilities to process vast amounts of data efficiently. 🚀💡
#ApacheSpark #BigData #DataEngineering #DistributedComputing #DataProcessing #RDD #SparkArchitecture #MachineLearning #DataScience #InMemoryProcessing #CloudComputing #Spark #ClusterManagement #TechTrends #DataAnalytics #DAG #JobScheduling #ETL #SparkJobs #BigDataTools