In this part, we will learn how AWS services solve volume challenges for organisations.
Amazon S3:
Store any amounts of object storage with scalability, availability, and security.
Amazon S3 is a secure, reliable, and price effective object storage that solves large-volume data storage challenges. Amazon S3 is scalable and can grow to any size needed for all your big data needs. It’s durable and can be used to store and retrieve any amount of data at any time from anywhere on the web. It implements industry-leading scalability, security, and performance.
Amazon S3 is the best place to store semistructured and unstructured data. This service is an object store, which means it can store just about any kind of discrete object in it. An object is how Amazon S3 refers to files.
To learn more about Amazon S3, choose each of the following two tabs.
- Features
- 99.999999999% durability
- Global resiliency
- Highly configurable access policies
- HTTP access
- Centrally manage data at scale
- Benefits
- Store anything from any source
- Highly scalable
- Secure object storage
- Cost-effective object storage

Amazon S3 is the fundamental storage service for most analytics workloads. It can store the widest variety of data types and data sources—structured, semistructured, and unstructured. Data can be moved from cloud and on-premises locations to Amazon S3. From there, data can be accessed by AWS and third-party analytics, AI, and ML services.
There are three ways Amazon S3 helps as a storage solution for high-volume data needs.
Decoupling:
With Amazon S3, you can separate the way you store data from the way you process it. This is known as decoupling storage from processing. You might have separate buckets for raw data, temporary processing results, and final results.
Parallelization:
With Amazon S3, you can access any of these buckets from any process, in parallel, without negatively impacting other processes.
Centralize Datasets:
Amazon S3 becomes a central location to store analytical datasets, providing access for multiple analytic processes at the same time. This allows the solution to avoid the costly process of moving data between the storage system and processing system.
AWS Lake Formation :
Build, manage, and secure data lakes faster and more conveniently.
Organizations need a scalable way to store, manage, and access structured and unstructured data, and run different types of analytics in real time. Organizations can solve these large volume challenges with a data lake—a centralized repository to store all structured and unstructured data at any scale.
AWS Lake Formation makes it convenient to ingest, clean, catalog, transform, and secure data and make it available for analysis and ML. With the AWS Lake Formation console you can discover data sources, set up transformation jobs, and move data to an Amazon S3 data lake. With the console you can also centralize job orchestrations, and monitor job processing. Lake Formation automatically configures underlying AWS services to ensure compliance with defined policies.
To learn more about Lake Formation, choose each of the following two tabs.
- Features
- Data lake foundation on Amazon S3
- Streamlined and centralized data management
- Straightforward data governance and security
- Enforce permissions with built-in integrations for data integration and big data processing
- Database style fine-grained permissions on resources
- Unified Amazon S3 permissions
- Benefits
- Build data lakes quickly
- Remove server management
- Centrally manage access to datasets
- Streamline security and governance at scale
- Seamless data movement between data lakes and purpose-built data and analytics services
- Conveniently share your data securely within and outside your organization
The following diagram shows Lake Formation in relation to Amazon S3 and Amazon analytics services.
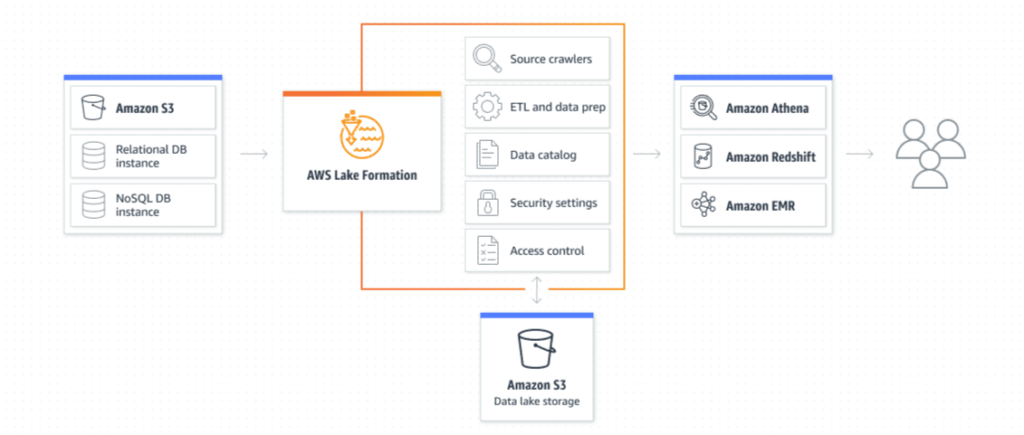
AWS Lake Formation provides a central console from which you can ingest data and set up processes to prepare that data for analysis. Incoming content from Amazon S3 and other locations, such as databases, can be cleansed, normalized, and cataloged. The prepared data is also stored on Amazon S3, ready for access by Amazon analytics services.
Amazon Redshift
Use cloud data warehousing with the best price performance
Massive numbers of analytical requests easily overload transactional systems. When large numbers of queries are run against the database, it dramatically slows down insert, update, and delete operations. A specific type of database for large-volume structured data is a data warehouse. It is one of the most common for analytics.
Amazon Redshift is a fast, scalable data warehouse that makes it convenient and cost effective to analyze all your data across your data warehouse and data lake. Amazon Redshift delivers faster performance than other data warehouses by using ML, massively parallel query processing, and columnar storage on high-performance disks. You can set up and deploy a new data warehouse in minutes. You can run queries across petabytes of data in your Amazon Redshift data warehouse, and exabytes of data in your data lake built on Amazon S3. Amazon Redshift implements columnar indexing to achieve the right performance for analytical workloads.
To learn more about Amazon Redshift, choose each of the following two tabs.
- Features
- Rapidly query datasets ranging in size from gigabytes to petabytes
- Visualize queries and analysis and share anywhere
- Automate building, training, and tuning ML models for business intelligence
- Benefits
- Efficient storage and high-performance query processing
- Agile scaling of analytics workloads on all your data without managing your data warehouse infrastructure
- Price-performance at scale
The following illustration shows the roles Amazon Redshift plays in analysis workflows.
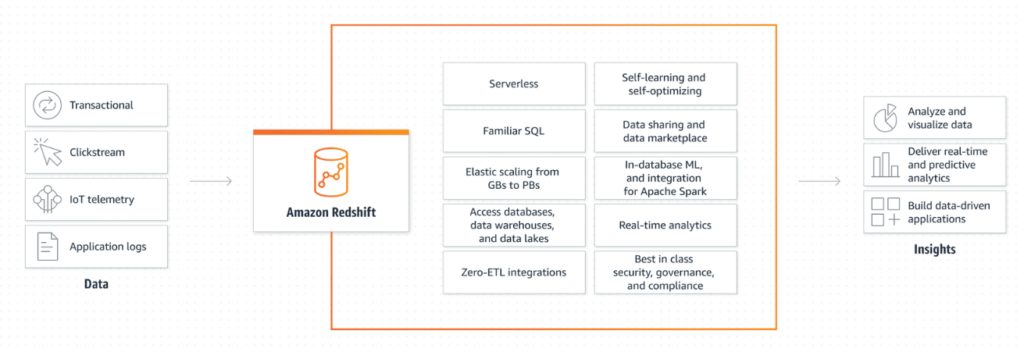
Amazon Redshift analyzes large volumes of data across data warehouses, operational databases, and data lakes to deliver the best price performance at any scale. Data lakes combined with Amazon Redshift data warehouses are an effective way to complement data stored in the data warehouse.