Data engineering skills encompass various aspects such as security, data management, DataOps, data architecture, and software engineering. Data engineers need to understand how to evaluate data tools and their integration across the data engineering lifecycle. It’s essential to grasp how data is generated in source systems and how it’s utilized by analysts and data scientists to create value. Moreover, data engineers must juggle multiple complex elements and continually optimize along axes like cost, agility, scalability, simplicity, reuse, and interoperability.

In the past, data engineers primarily worked with a few powerful and monolithic technologies like Hadoop, Spark, Teradata, and Hive. Their responsibilities included cluster administration, maintenance, managing overhead, and developing pipeline and transformation jobs. However, the landscape has evolved significantly, with modern data tools abstracting and simplifying workflows. Consequently, data engineers now focus on integrating the simplest, most cost-effective, and best-of-breed services to deliver value to the business. They also design agile data architectures that evolve with emerging trends.
What are some things a data engineer does not do? A data engineer typically does not directly build ML models, create reports or dashboards, perform data analysis, build key performance indicators (KPIs), or develop software applications. A data engineer should have a good functioning understanding of these areas to serve stakeholders best.
Despite their broad skill set, data engineers typically do not directly build ML models, create reports or dashboards, perform data analysis, develop key performance indicators (KPIs), or build software applications. However, they should have a functional understanding of these areas to effectively serve stakeholders.
Data Maturity and Data Engineer 🚀📊
The complexity of data engineering within a company is heavily influenced by its level of data maturity. Data maturity refers to the progression towards increased utilization, capabilities, and integration of data across the organization. However, data maturity is not solely determined by a company’s age or revenue. For instance, an early-stage startup may exhibit greater data maturity compared to a century-old corporation with significant annual revenues. What truly matters is how effectively data is utilized as a competitive advantage.
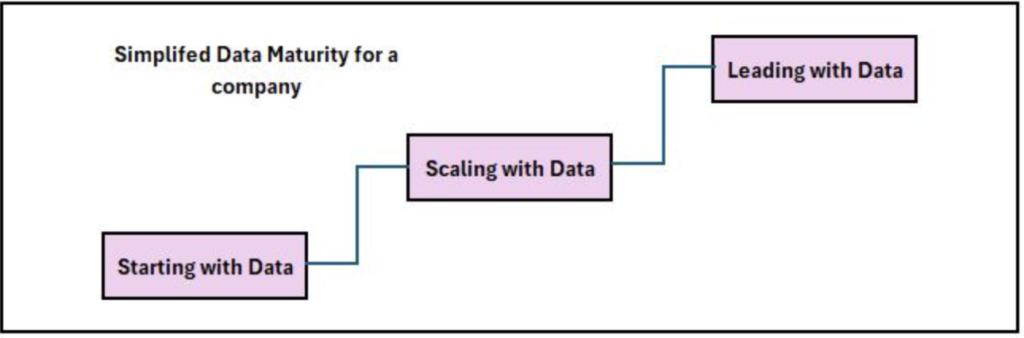
Various data maturity models exist, such as Data Management Maturity (DMM), each offering its own perspective on assessing and improving data maturity. However, selecting a suitable model for data engineering purposes can be challenging due to the complexity and diversity of available options. Therefore, we’ve devised a simplified data maturity model comprising three stages: starting with data, scaling with data, and leading with data. Let’s delve into each stage and explore the typical responsibilities of a data engineer at each phase.
Stage 1. Starting with Data
When a company is just starting to embrace data, it’s in the early stages of its data maturity journey. At this point, goals may be fuzzy or entirely undefined. Data architecture and infrastructure are still in the initial phases of planning and development, with low or nonexistent adoption and utilization rates. The data team is typically small, often consisting of just a few members who wear multiple hats, such as data scientists or software engineers. The primary objective for a data engineer at this stage is to move quickly, gain traction, and deliver value.
However, there’s often a gap in understanding how to derive value from data practically, despite a desire to do so. Reports and analyses lack formal structure, and requests for data tend to be ad hoc. While the allure of diving into machine learning (ML) might be strong, it’s advisable to proceed with caution. Many data teams have found themselves stuck or falling short when attempting to implement ML without first establishing a solid data foundation.
To navigate this stage effectively, a data engineer should focus on several key tasks:
- Securing buy-in from key stakeholders: It’s essential to garner support from executive management and ideally have a sponsor for critical initiatives aimed at designing and building a data architecture aligned with the company’s goals.
- Defining the right data architecture: Since dedicated data architects may not be available, the data engineer often takes on the responsibility of defining a suitable data architecture. This involves aligning with business goals and identifying the competitive advantage to be gained from the data initiative.
- Identifying and auditing relevant data: Determine which data will support key initiatives and ensure that it aligns with the designed data architecture.
- Building a solid data foundation: Lay the groundwork for future data analysts and data scientists by creating a robust data foundation that enables the generation of reports and models delivering competitive value. This may involve generating reports and models initially until a dedicated team is in place.
Navigating this stage requires careful attention to potential pitfalls. Here are some tips:
- Focus on quick wins: Establishing the importance of data within the organization is crucial, but be mindful that quick wins may lead to technical debt. Have a plan in place to address this debt to avoid friction in future deliveries.
- Communicate and collaborate: Engage with stakeholders across departments to gather perspectives and feedback. Avoid working in silos to ensure that efforts are aligned with the organization’s needs.
- Embrace simplicity: Avoid unnecessary technical complexity and opt for off-the-shelf solutions wherever possible. Reserve custom solutions and coding for areas where they provide a competitive advantage.
Stage 2. Scaling with Data
At this stage, the company has progressed beyond ad hoc data requests and has implemented formal data practices. The focus now shifts towards creating scalable data architectures and preparing for a future where the company is truly data-driven. Data engineering roles transition from generalists to specialists, with individuals specializing in specific aspects of the data engineering lifecycle.
In organizations at stage 2 of data maturity, the goals of a data engineer include:
- Establishing formal data practices: Implementing structured processes and methodologies for managing and utilizing data effectively throughout the organization.
- Creating scalable and robust data architectures: Designing architectures capable of handling increasing volumes of data while maintaining reliability and performance.
- Adopting DevOps and DataOps practices: Integrating development, operations, and data teams to streamline the data engineering lifecycle and improve collaboration and efficiency.
- Building systems that support ML: Developing platforms and frameworks to facilitate the training, deployment, and management of machine learning models.
- Continuing to avoid undifferentiated heavy lifting: Focusing on leveraging existing tools and technologies to minimize unnecessary complexity and customization, while prioritizing efforts that provide a competitive advantage.
However, there are several issues to be mindful of at this stage:
- Avoiding the allure of bleeding-edge technologies: While it may be tempting to adopt the latest technologies, decisions should be driven by the value they deliver to customers rather than social proof from Silicon Valley companies.
- Recognizing the main bottleneck for scaling: While technology infrastructure is important, the primary bottleneck for scaling is often the data engineering team itself. Emphasize solutions that are easy to deploy and manage to increase the team’s throughput.
- Shifting focus from technology to pragmatic leadership: Rather than positioning oneself solely as a technologist, data engineers should focus on pragmatic leadership and communication, educating other teams about the practical utility of data and how to effectively leverage it. This involves transitioning towards the next maturity stage and fostering collaboration across the organization.
Stage 3. Leading with Data
At this stage, the company is data-driven. The automated pipelines and systems created by data engineers allow people within the company to do self-service analytics and ML. Introducing new data sources is seamless, and tangible value is derived. Data engineers implement proper controls and practices to ensure that data is always available to the people and systems. Data engineering roles continue to specialize more deeply than in stage 2.
In organizations in stage 3 of data maturity, a data engineer will continue building on prior stages, plus they will do the following:
- Create automation for the seamless introduction and usage of new data
- Focus on building custom tools and systems that leverage data as a competitive advantage
- Focus on the “enterprisey” aspects of data, such as data management (including data governance and quality) and DataOps
- Deploy tools that expose and disseminate data throughout the organization, including data catalogs, data lineage tools, and metadata management systems
- Collaborate efficiently with software engineers, ML engineers, analysts, and others
- Create a community and environment where people can collaborate and speak openly, no matter their role or position
Issues to watch out for include the following:
- At this stage, complacency is a significant danger. Once organizations reach stage 3, they must constantly focus on maintenance and improvement or risk falling back to a lower stage.
- Technology distractions are a more significant danger here than in the other stages. There’s a temptation to pursue expensive hobby projects that don’t deliver value to the business. Utilize custom-built technology only where it provides a competitive advantage.
Background and Skills of a Data Engineer
Data engineering is a rapidly evolving field, and many individuals are curious about how to embark on a career as a data engineer. Due to its relatively recent emergence, formal training programs specific to data engineering are scarce. Universities typically lack standardized data engineering pathways, and while some data engineering boot camps and online tutorials exist, they often cover disparate topics without a cohesive curriculum.
Individuals entering the field of data engineering come from diverse educational backgrounds, career paths, and skill sets. Regardless of background, aspiring data engineers should anticipate dedicating a significant amount of time to self-study. This book serves as a valuable starting point, aiming to provide readers with a foundational understanding of the knowledge and skills essential for success in the field.
For those transitioning into data engineering from related fields, such as software engineering, ETL development, database administration, data science, or data analysis, the journey tends to be smoother. These adjacent disciplines offer a level of familiarity with data concepts and roles within organizations, along with relevant technical skills and problem-solving abilities that translate well into data engineering.
Despite the absence of a standardized path, there exists a fundamental body of knowledge that we consider essential for data engineers to possess. A successful data engineer must have a comprehensive understanding of both data principles and technology. On the data front, this entails familiarity with best practices in data management. On the technology side, data engineers must be knowledgeable about various tools, their interactions, and the trade-offs involved. This requires proficiency in software engineering, DataOps practices, and data architecture.
Moreover, data engineers must grasp the needs of data consumers, such as data analysts and data scientists, and comprehend the broader organizational implications of data. Data engineering is a multidisciplinary practice; effective data engineers approach their responsibilities from both business and technical perspectives, understanding the symbiotic relationship between data and organizational objectives.

Business Responsibilities
The macro responsibilities outlined in this section are not exclusive to data engineers but are essential for anyone working in data or technology fields. Given the abundance of resources available to learn about these areas, we’ll list them briefly for brevity:
- Effective Communication: Being able to communicate effectively with both technical and non-technical stakeholders is paramount. Establishing rapport and trust across the organization is crucial. Understanding organizational hierarchies, communication dynamics, and existing silos is invaluable for success.
- Business and Product Requirements: Understanding how to scope and gather business and product requirements is essential. It’s important to know what needs to be built and ensure alignment with stakeholders. Developing an awareness of how data and technology decisions impact the business is critical.
- Cultural Understanding: Recognize the cultural foundations of Agile, DevOps, and DataOps practices. While many perceive these as purely technological solutions, they fundamentally rely on cultural buy-in across the organization.
- Cost Management: Controlling costs is key to success. Strive to keep costs low while delivering significant value. Optimize for time to value, total cost of ownership, and opportunity cost. Monitoring costs proactively helps prevent surprises.
- Continuous Learning: The data field evolves rapidly, and continuous learning is essential. Successful individuals in the field excel at acquiring new skills while strengthening fundamental knowledge. They are adept at filtering new developments, discerning relevance to their work, identifying immature concepts, and distinguishing passing fads. Staying informed about industry developments and mastering the art of learning is crucial.
A successful data engineer understands the broader business landscape and seeks to deliver significant value. Effective communication, both technical and non-technical, plays a pivotal role in success. Data teams often thrive based on their ability to communicate effectively with stakeholders, as success or failure is seldom purely a technological issue. Navigating the organizational landscape, managing requirements, controlling costs, and embracing continuous learning are key differentiators for data engineers aiming for long-term success.
Technical Responsibilities
Understanding how to construct architectures that optimize both performance and cost is crucial for a data engineer. These architectures, along with their constituent technologies, serve as the foundation for the data engineering lifecycle. The stages of this lifecycle include:
- Generation
- Storage
- Ingestion
- Transformation
- Serving
Embedded within the data engineering lifecycle are several core elements:
- Security
- Data management
- DataOps
- Data architecture
- Orchestration
- Software engineering
Here, we delve into some of the tactical data and technology skills essential for data engineers. These skills will be further explored in subsequent chapters.
One common question is whether a data engineer should possess coding skills. The short answer is yes. Data engineers should be proficient in production-grade software engineering. While the nature of software development projects undertaken by data engineers has evolved in recent years, with managed services replacing low-level programming tasks, proficiency in software engineering remains crucial. Even in this evolving landscape, software engineering best practices offer a competitive advantage. Data engineers capable of delving into the architectural intricacies of a codebase provide their companies with an edge when faced with specific technical challenges. In essence, data engineers are still software engineers, among their various other roles.
Which programming languages should a data engineer know? We categorize data engineering programming languages into primary and secondary categories:
Primary languages:
- SQL: The most common interface for databases and data lakes, SQL has reemerged as the lingua franca of data.
- Python: Often considered the bridge language between data engineering and data science, Python underlies numerous data tools and frameworks.
- JVM languages (Java, Scala): Prevalent in various Apache open-source projects such as Spark, Hive, and Druid.
- bash: The command-line interface for Linux operating systems, essential for scripting and performing OS operations in data pipelines.

The Unreasonable Effectiveness of SQL
With the rise of MapReduce and the onset of the big data era, SQL initially seemed outdated. However, subsequent developments have revitalized SQL's relevance in the data engineering lifecycle. Tools like Spark SQL, Google BigQuery, Snowflake, Hive, and others leverage SQL's declarative, set-theoretic semantics to process massive datasets efficiently. Moreover, SQL is now supported by various streaming frameworks such as Apache Flink, Beam, and Kafka. Given these advancements, we believe that data engineers should possess a high level of proficiency in SQL.
Does this mean that SQL is the ultimate solution for all data engineering tasks? Not necessarily. While SQL is indeed a potent tool capable of swiftly tackling complex analytics and data transformation challenges, it's important to recognize that time is a critical constraint for data engineering teams. Thus, engineers should prioritize tools that offer simplicity and high productivity. Additionally, data engineers benefit from mastering the art of combining SQL with other operations, either within frameworks like Spark and Flink or through orchestration mechanisms that integrate multiple tools. Furthermore, familiarity with modern SQL features for handling JSON parsing and nested data, along with leveraging SQL management frameworks like dbt (Data Build Tool), can enhance a data engineer's capabilities.
A proficient data engineer also knows when SQL may not be the optimal choice for a given task and can select and code in an appropriate alternative. For example, while a SQL expert might be able to craft a query to stem and tokenize raw text in a natural language processing (NLP) pipeline, they would recognize that utilizing native Spark is a more efficient approach. Thus, versatility in selecting the right tool for the job is a hallmark of an effective data engineer.Data engineers may find it beneficial to cultivate proficiency in secondary programming languages, which can include R, JavaScript, Go, Rust, C/C++, C#, and Julia. Mastery of these languages becomes essential when they are widely adopted within the company or utilized alongside domain-specific data tools.
For example, JavaScript has emerged as a favored language for implementing user-defined functions in cloud data warehouses. Similarly, companies heavily reliant on Azure and the Microsoft ecosystem may require expertise in languages like C# and PowerShell. These languages serve as integral components of data engineering workflows within such environments.
Keeping Pace in a Fast-Moving Field
Once a new technology rolls over you, if you’re not part of the steamroller, you’re part of the road.
Stewart Brand