SQL (Structured Query Language) was specifically created for managing and manipulating relational databases. It offers commands and statements that enable users to connect to databases, retrieve and update data, design database structures, and execute a variety of data-related tasks. Further information is provided below:
Definition and Purpose of SQL:
SQL, or Structured Query Language, is a declarative language designed for managing relational databases. It allows users to interact with databases by constructing queries to access, modify, and manage structured data. Regardless of the underlying database management system, SQL offers a standardized and efficient way to work with databases.
Due to its adaptability and efficiency in maintaining relational databases, SQL is frequently used in data science and analytics. Here are the main reasons for SQL’s high value:
- Standardization: SQL provides a standardized way of managing and manipulating data across different database management systems, ensuring consistency and reliability.
- Ease of Use: With its relatively simple syntax, SQL allows users to perform complex queries and data manipulations without extensive programming knowledge.
- Versatility: SQL can handle a wide range of data tasks, from retrieving and modifying data to constructing and managing database structures.
- Efficiency: SQL is designed to process large volumes of data quickly and efficiently, making it ideal for data-intensive applications.
- Powerful Querying Capabilities: SQL enables users to specify criteria and conditions to retrieve exactly the information they need, making data analysis more precise.
- Data Integrity: SQL supports the enforcement of data constraints, helping to maintain the accuracy and consistency of the data within a database.
- Scalability: SQL databases can scale to handle increasing amounts of data and users, making them suitable for both small and large-scale applications.
- Security: SQL includes robust tools for managing data security and permissions, ensuring that only authorized users can access or modify sensitive information.
- Integration with Other Technologies: SQL can easily integrate with various programming languages, tools, and frameworks, enhancing its functionality in diverse applications.
- Support for Analytical Functions: SQL includes built-in functions for performing complex calculations and data transformations, making it invaluable for data analysis and reporting.
These attributes make SQL an indispensable tool in the field of data science and analytics. 📊✨
SQL Constraints
SQL constraints allow you to define rules for the data in a table. These constraints restrict the kinds of data that can be entered into a table, ensuring the reliability and accuracy of the data. If there is a violation between a constraint and a data action, the action is halted.
Constraints can be applied at the column level or the table level. Column-level constraints affect only the specified column, while table-level constraints apply to the entire table. This flexibility allows for precise control over the data integrity and structure within the database. 🛡️📊
In SQL the following constraints are frequently applied :
- NOT NULL: This constraint ensures that a column cannot have a NULL value by using the NOT NULL flag. It mandates that every entry in the column must contain a value.
- UNIQUE: A unique constraint ensures that each value in a column is distinct. It prohibits duplicate entries within the column, maintaining data integrity.
- PRIMARY KEY: A primary key constraint is a combination of NOT NULL and UNIQUE. It uniquely identifies each row in a table, serving as a unique identifier for each record.
- FOREIGN KEY: This constraint prevents actions that would break linkages between tables. It establishes a relationship between two tables based on a column in one table referencing the primary key of another table.
- CHECK: The CHECK constraint verifies if the values in a column meet a certain requirement or condition. It allows you to define custom conditions that must be satisfied by the data in the column.
- DEFAULT: If no value is specified for a column, the DEFAULT constraint sets a default value for that column. It ensures that a default value is assigned to the column if no explicit value is provided during insertion. By utilizing operations like GETDATE, the DEFAULT constraint can also be utilized to insert system data ()
- CREATE INDEX: This statement is used to easily create an index on a column or a set of columns in a table. Indexes improve the performance of data retrieval operations by facilitating quick access to data stored in the database.
These constraints play a crucial role in defining and maintaining the structure and integrity of data within a database. 🛡️🗂️
Various Key Types
What is the Key ?
In relational database management systems (RDBMS), keys are fields that serve various purposes in tables:
- Establishing Connections Between Tables:
- Keys, particularly foreign keys, establish relationships between tables by referencing primary keys or unique keys in other tables.
- This relationship ensures data integrity and facilitates data retrieval through related tables.
- Maintaining Table Individuality:
- Primary keys uniquely identify each record within a table, ensuring that each row has a distinct identity.
- This uniqueness preserves the individuality of records and prevents duplication or ambiguity.
- Ensuring Data Accuracy and Consistency:
- Keys, such as primary keys and unique keys, enforce constraints on data, ensuring that only valid and accurate information is stored in the database.
- Constraints imposed by keys maintain the consistency and reliability of data throughout the database.
- Speeding Up Data Retrieval with Indexes:
- Keys, particularly primary keys and columns with unique constraints, can be indexed to improve the performance of data retrieval operations.
- Indexes enable faster access to data by organizing data in a structured manner and facilitating efficient search and retrieval.
By fulfilling these roles, keys play a crucial part in the structure, integrity, and performance of databases in RDBMS systems. 🗝️🏛️
Here’s a concise list of key types in SQL:
- Primary Key (PK)
- Foreign Key (FK)
- Unique Key (UK)
- Composite Key
- Alternate Key
- Super Key
- Candidate Key (CK)
Understanding these key types is fundamental for designing robust and efficient databases in SQL. 🗝️🛡️
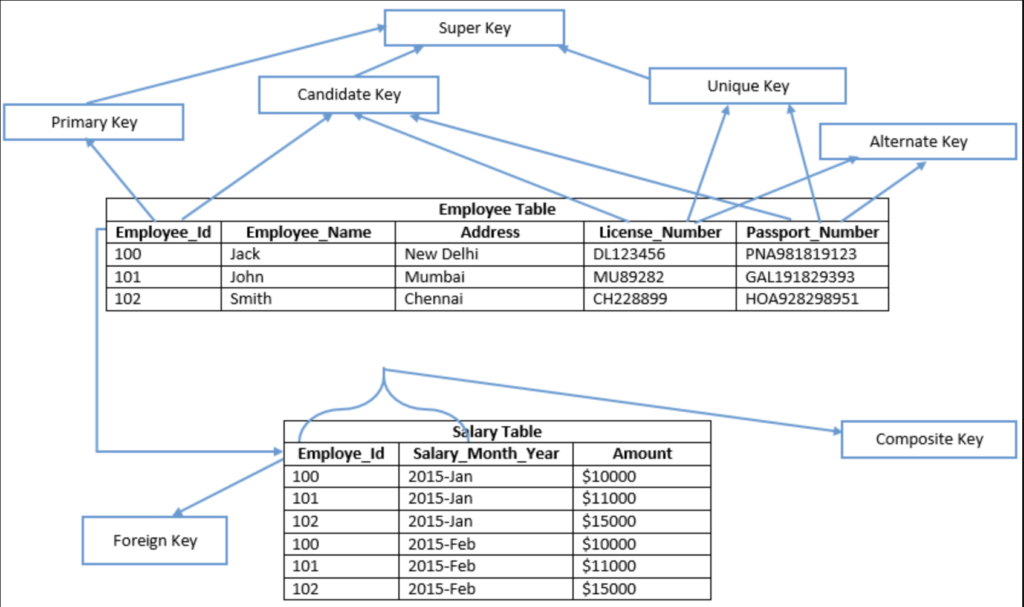
Candidate Key:
A candidate key is a potential primary key for a table, which means it has the potential to uniquely identify each record. While there may be multiple candidate keys in a table, only one is ultimately chosen as the primary key. For instance, in a table storing employee information, candidate keys could include fields such as License Number, Employee ID, and Passport Number. However, only one of these candidate keys would be selected to serve as the primary key for the table.
Primary Key:
- A primary key uniquely identifies each record in a table.
- It must contain unique values and cannot be NULL.
- Typically, it’s implemented using a single column, but composite primary keys (using multiple columns) are also possible.
- Used to enforce entity integrity.
# CREATE TABLE Statement
CREATE TABLE Employee (
Employee_Id INT PRIMARY KEY,
-- Other columns
);
# ALTER TABLE Statement
ALTER TABLE Employee
ADD CONSTRAINT PK_Employee PRIMARY KEY (Employee_Id);
Foreign Key:
- A foreign key establishes a link between two tables by referencing the primary key or a unique key in another table.
- It ensures referential integrity by enforcing relationships between related tables.
- Prevents actions that would create orphaned records (records with no corresponding parent record).
Unique Key:
- A unique key constraint ensures that all values in a column (or set of columns) are distinct and not NULL.
- Unlike a primary key, a unique key allows NULL values.
- Used to enforce uniqueness but does not automatically imply a relationship between tables.
Alternate Key:
- An alternate key is a candidate key that is not selected as the primary key.
- While it’s unique, it’s not chosen as the primary means of identifying records.
- Provides an alternative way to uniquely identify records.
Composite Key:
- A composite key is a combination of two or more columns that uniquely identify a record in a table.
- It’s used when a single column cannot uniquely identify records, but the combination of multiple columns does.
Super Key:
- A super key is a set of attributes (columns) that uniquely identifies each record in a table.
- It may contain more attributes than necessary to uniquely identify records, making it a superset of a candidate key.
- Super keys help in identifying candidate keys.
Understanding these key types is crucial for designing well-structured databases and maintaining data integrity in SQL systems. 🗝️🛡️